CloudForms by Red Hat has extensive reporting and predictive analysis built into the product. But what if you already have a reporting engine? Or want to do analysis not already built into the system? This project was created as an example of using Cloud Forms with external reporting tools (our example uses R). Take special care that you can miss context to the data, as there is a lot of state built into the product, and for guaranteed correctness, use the builtin “integrate” functionality.
CloudForms by Red Hat has extensive reporting and predictive analysis built into the product. But what if you already have a reporting engine? Or want to do analysis not already built into the system? This project was created as an example of using Cloud Forms with external reporting tools (our example uses R). Take special care that you can miss context to the data, as there is a lot of state built into the product, and for guaranteed correctness, use the builtin “integrate” functionality.
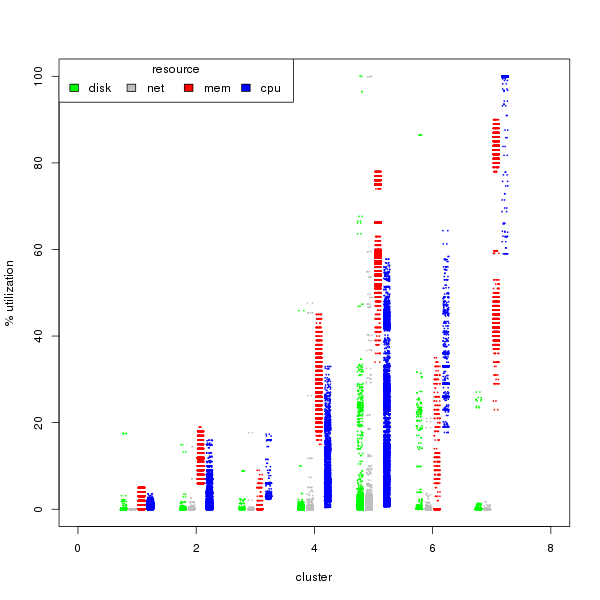
Both the data collection and the analyses are fast for what they are, but aren’t particularly quick. Be patient: calculating the CPU confidence intervals of 73,000 values across 120 systems took about 90 seconds (elapsed time) on a 2011 laptop.
Required R libraries
forecast
DBI
RPostgreSQL
Installing RPostgreSQL required postgresql-devel rpm on my Fedora 14 box
See: collect.R for example to get started. Full code is available on github.
Notes on confidence intervals
Confidence intervals are the “strength” of likelihood # a value with fall within a given range. The 80% confidence interval is the set of values expected to fall within the range 80% of the time. It is a smaller range than the 95% interval, and should be considered more likely. E.g. if are going to hit your memory threshold within the 80% interval, look to address those limits before those that only fall within the 95% interval.
Notes on frequencies
Frequencies within the functions included are multiples of collected data. Short term metrics are collected at 20 second intervals. Rollup
metrics are 1 hour intervals. Example: for 1 minute intervals with short term metrics, use frequency of 3.
Notes of fields
These are column names from the CF db. The default field is cpu_usage_rate_average. I also recommend looking at mem_usage_absolute_average.
Notes on graphs
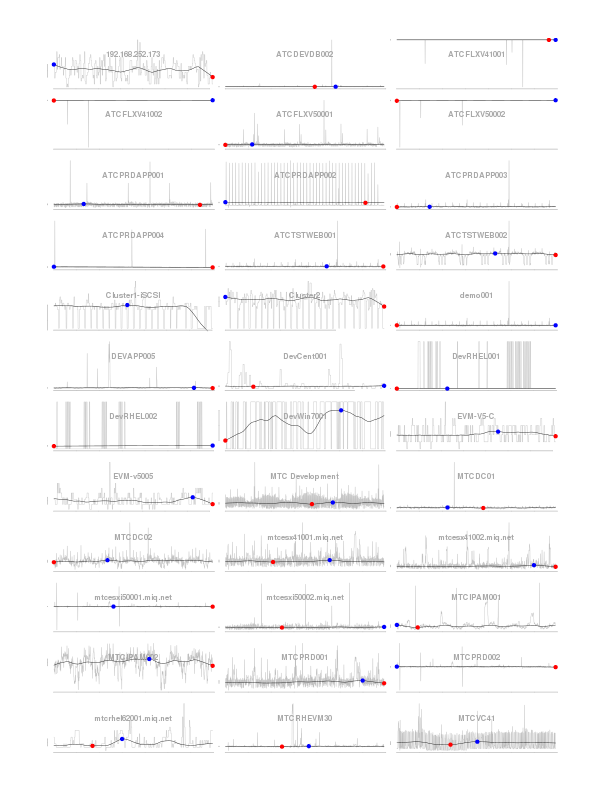
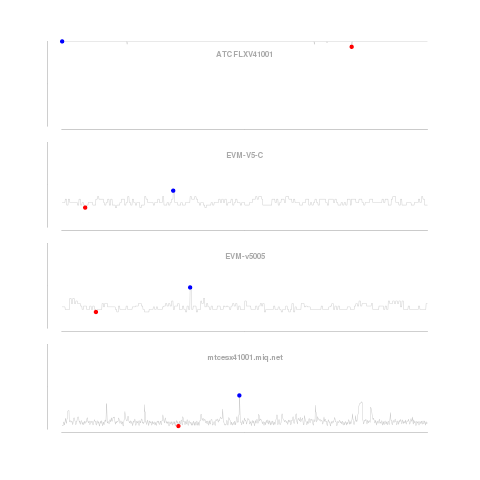
Graphs for the systems are shown for the first X systems (up to “max”) with sufficient data to perform the analysis (# of data points > frequency * 2) and that have a range of data, e.g. min < max. Red point = min, blue point = max.
Example images
*.raw.png are generated from the short term metrics. The others from the rollup data.