 Finding largest cliques (completely connected sub-graph components) is hard. The best algorithms have run times proportional to 3^(#nodes/3). Triple the nodes = nine times the run length. So what’s a guy without a supercomputer to do but start looking for shortcuts?
Finding largest cliques (completely connected sub-graph components) is hard. The best algorithms have run times proportional to 3^(#nodes/3). Triple the nodes = nine times the run length. So what’s a guy without a supercomputer to do but start looking for shortcuts?
Shortcut 1: Maximize for your goals
My interest is in characterizing a network, in part, through largest clique size. Since the interest is in size, not quantity, I can start looking for cliques of size N+1 as soon as I find one of size N.
Shortcut 2: Estimate
I’m interested in specific types of networks, social networks. And we can tune for that through size estimation.
The networks I’ve run through my clique analysis are public (mailing lists, twitter feeds, etc) and generally demonstrate maximum clique size relative to number of active participants and independent of the time observed. I’ve looked at networks sampled for a week to complete observations of 10+ years of conversations.
I have only found once case where the maximum clique size was smaller than ln(# nodes)/2 for these directed networks. When artificially forcing them to undirected networks, the maximum clique size is around double.
Shortcut 3: Cleanse the Data
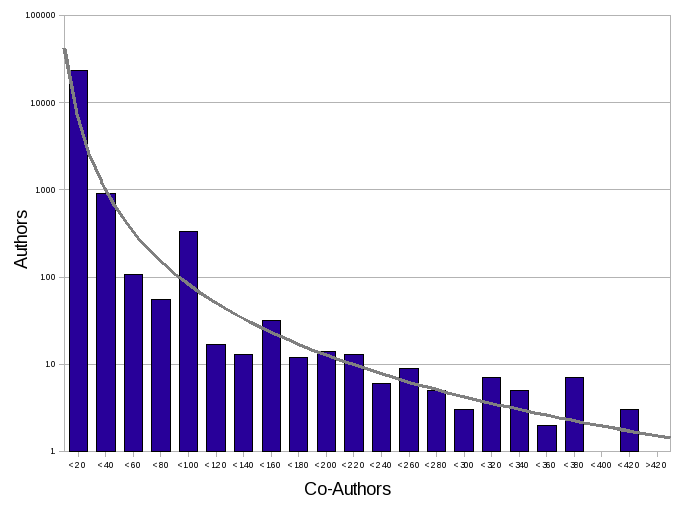
Now that I have estimated size, every node with fewer edges can be ignored. With that amounting to around (1-1/n)%, for n less than the estimated size, we can cut down the search space.
Shortcut 4: Order your Data
With looking for the largest clique, the more links a node has, the more likely it’s a member of that clique. So, when you are selecting which nodes to start with, start with the ones with most links. The sooner you locate larger cliques, the sooner you can stop looking for smaller ones.
Results
Here’s where the “laptop test” comes in: using just a subset of the above, I was able to locate 9-member cliques in an undirected 2,000-node 5,500-edge network in under 5 seconds. By comparison, on the same machine, it took 5 minutes to locate them using the igraph library in R.
R’s igraph, sadly, ignores edge direction in locating cliques. But, a run of the above using my code with edge direction completed in about 0.5 seconds.
As an example for larger graphs, I located 15-member cliques in an undirected 75,000-node 220,000-edge network in 20 hours. R topped out in memory before reaching this size network, and was unable to complete.
Update: It’s been pointed out to me that this has scaled pretty close to n^3.












{kind=link}
{kind=link}
{kind=link}